AWS AI/ML and Analytics Services
Not sure you’re ready?
Take the ~3-minute readiness diagnostic and see where you stand.
Every time a customer interacts with an enterprise—whether swiping a credit card, clicking a web link, or submitting a support ticket—they leave a digital fingerprint. Left alone, this avalanche of information is merely expensive digital weight. Yet, when properly harnessed, it becomes the predictive engine of a modern business. By separating the storage of raw data from the computational engines used to analyze it, AWS allows organizations to look backward to understand what happened, and look forward to predict what will happen next.
Before we can extract insights, we must first capture and organize the raw material. In legacy on-premises environments, data was often siloed: the finance department had one database, human resources had another, and marketing had a third. Analytics requires a unified view.
To solve this, organizations build data lakes.
A data lake is a centralized repository that stores structured and unstructured data at any scale.
Unlike traditional databases that require data to be neatly formatted before it is saved, a data lake accepts everything—video files, server logs, CSVs, and JSON files—in its native format. In the AWS ecosystem, Amazon S3 serves as the primary storage layer for AWS data lakes because of its virtually infinite scalability and high durability.
However, data rarely sits still. To architect analytical workflows, data must be routed, cleaned, and formatted.
- AWS Data Pipeline is a web service that facilitates processing data between different AWS compute and storage services. By acting as an orchestrator, AWS Data Pipeline automates the movement and transformation of data on a scheduled basis, ensuring that data arrives where it is needed reliably.
- AWS Glue, by contrast, is highly specialized for analytics preparation. AWS Glue is a serverless data integration service that performs extract, transform, and load (ETL) operations. Imagine a massive shipment of disorganized inventory arriving at a warehouse; AWS Glue is the automated sorting system that cleans, categorizes, and organizes it. Ultimately, AWS Glue prepares data for analytics and machine learning, ensuring that downstream tools ingest high-quality, readable information.
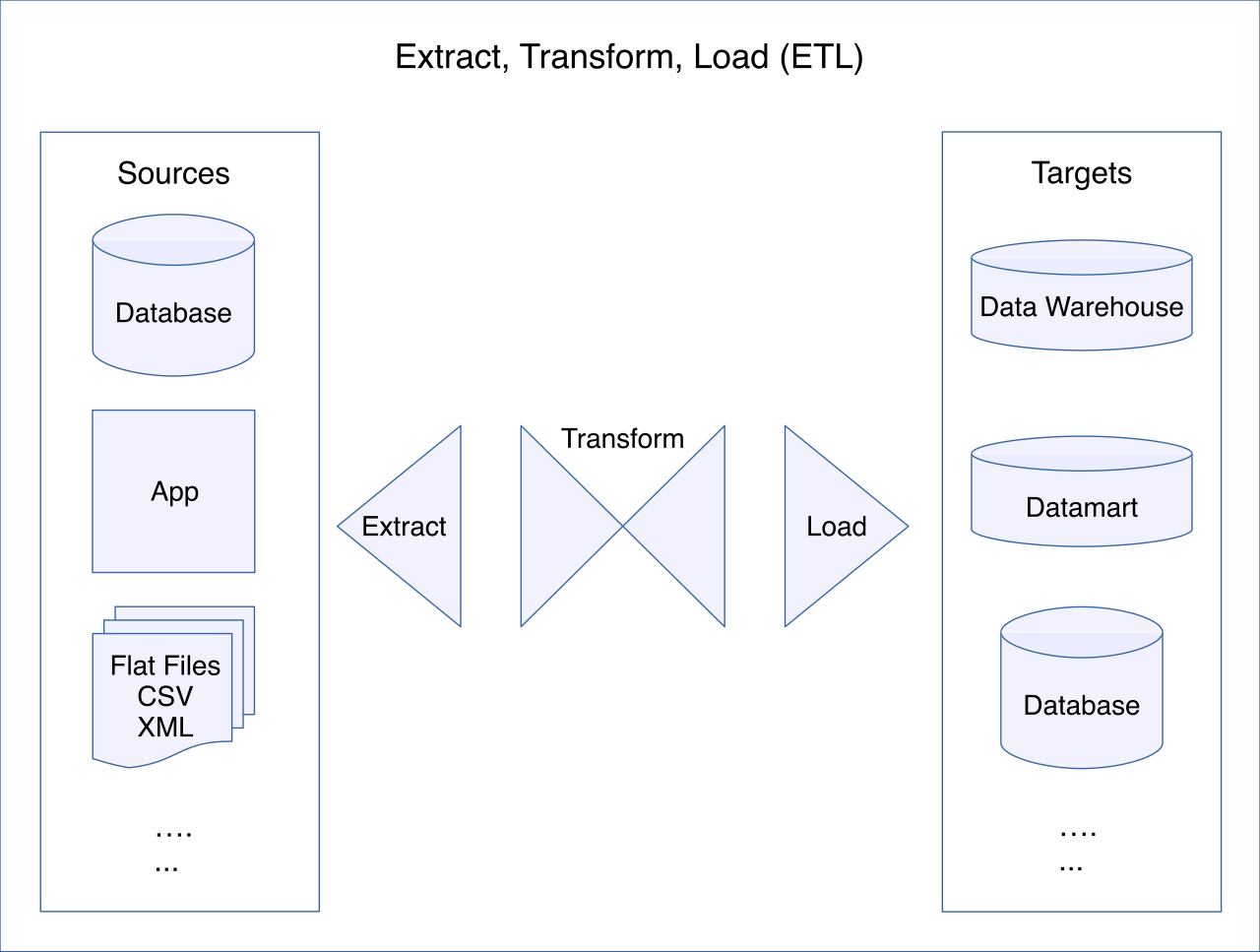
Once data is centralized in Amazon S3 and prepared by AWS Glue, how do we ask questions of it? AWS provides three distinct computational engines, depending on the scale and structure of your query.
Amazon Athena: The Ad-Hoc Query Engine
If you need immediate answers from a raw CSV file sitting in S3, you do not want to spend weeks building a database. Amazon Athena is a serverless interactive query service that solves this exact problem. Conceptually, Amazon Athena analyzes data directly stored in Amazon S3. You pay only for the data scanned during your query. Because Amazon Athena uses standard SQL to query data, business analysts can begin exploring massive datasets immediately without learning proprietary languages or provisioning servers.
Amazon Redshift: The Data Warehouse
When an enterprise needs to perform highly complex, structured reporting—such as generating end-of-year financial aggregations across millions of global transactions—they turn to Amazon Redshift. Amazon Redshift is a fully managed cloud data warehouse. While Athena queries data where it rests in a data lake, Redshift requires data to be loaded into its highly structured, performance-optimized disks. Like Athena, Amazon Redshift analyzes large-scale data using standard SQL, making it the backbone for traditional enterprise business intelligence.
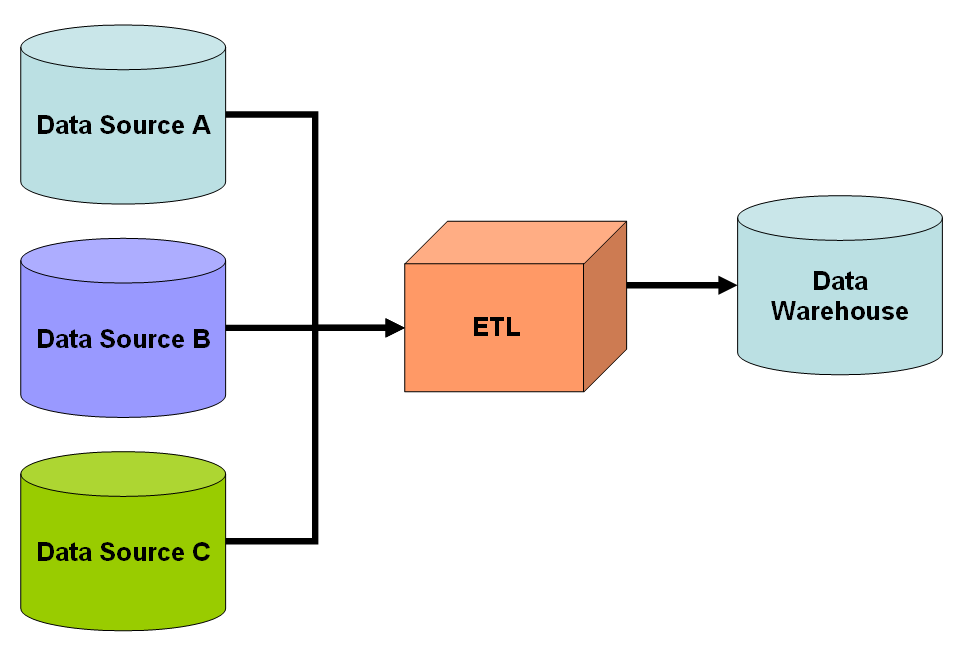
Amazon EMR: The Big Data Processor
Sometimes, the sheer volume or complexity of the data requires massive distributed processing power. Amazon EMR is a cloud big data platform designed specifically for this task. Amazon EMR supports open-source frameworks like Apache Hadoop and Apache Spark, allowing data scientists to run complex algorithms. To achieve this immense scale, Amazon EMR processes vast amounts of data across a cluster of Amazon EC2 instances, acting as a transient supercomputer that you can spin up, use to crunch petabytes of data, and terminate when finished.
Historical analysis is highly valuable, but what if a business needs to react to data as it happens?
When dealing with a continuous flow of information—such as stock market tickers, IoT sensor telemetry, or website clickstreams—you must use streaming services.
- Amazon Kinesis is an AWS service designed for collecting real-time streaming data. Rather than waiting for a daily batch upload, Amazon Kinesis processes large streams of data records in real time, allowing applications to react instantly.
- To capture this flowing water and store it for later analysis, AWS offers Amazon Kinesis Data Firehose. Acting exactly as its name implies, Amazon Kinesis Data Firehose reliably loads streaming data into data lakes and data stores (like Amazon S3 or Redshift) seamlessly.
Beyond standard data streams, IT professionals need to monitor the health of their applications in real-time. Amazon OpenSearch Service is an AWS service used to perform interactive log analytics. By ingesting application and server logs as they are generated, Amazon OpenSearch Service enables real-time application monitoring, allowing IT teams to detect and diagnose server failures the moment they occur.
Finally, all this data is useless if it cannot be communicated to stakeholders. Amazon QuickSight is a fully managed cloud-native business intelligence service. Rather than handing a spreadsheet to an executive, Amazon QuickSight enables the creation of interactive data dashboards. Furthermore, Amazon QuickSight allows users to share data visualizations across an organization, embedding critical business metrics directly into web portals and daily reports.
Data analytics tells you what happened yesterday. Machine learning (ML) tells you what will happen tomorrow.
At its core, machine learning automates pattern recognition in large datasets. Instead of programming explicit rules ("if X, then Y"), a machine learning model is trained on historical data to infer its own rules, allowing it to make predictions on data it has never seen before.
Building these models from scratch requires complex infrastructure, sophisticated algorithms, and massive compute power. Amazon SageMaker is a fully managed machine learning service designed to remove this heavy lifting. Think of it as a comprehensive workbench for data scientists.
- Amazon SageMaker provides tools to build machine learning models through integrated development environments.
- Amazon SageMaker provides tools to train machine learning models automatically scaling the necessary compute resources to process the training data.
- Once the model is accurate, Amazon SageMaker streamlines the deployment of machine learning models into production, turning a theoretical algorithm into a live API endpoint that applications can interact with.
Not every organization has a team of data scientists capable of using SageMaker. To democratize access to AI, AWS offers a suite of pre-trained AI services. These act as "cognitive APIs"—you simply send them data, and they return intelligent insights.
Vision and Analysis
- Amazon Rekognition is a cloud-based image and video analysis service.
- Amazon Rekognition uses machine learning to identify objects in images, such as detecting cars, pedestrians, or street signs in a photo.
- In security and media applications, Amazon Rekognition can perform facial recognition in videos.
- For platform moderation, Amazon Rekognition detects inappropriate content in visual media, automatically flagging unsafe images before they are published to a platform.

Text, Documents, and Insight
- Amazon Textract is a machine learning service designed to replace manual data entry. Amazon Textract automatically extracts text and data from scanned documents, turning a static PDF invoice into structured, queryable data.
- Once text is extracted, you can analyze its meaning. Amazon Comprehend is a natural language processing service. Amazon Comprehend uses machine learning to find insights in unstructured text, such as analyzing thousands of product reviews to determine overall customer sentiment (positive, negative, or neutral).
Voice, Speech, and Language Translation
- To convert spoken word to text, Amazon Transcribe is an automatic speech recognition service. Amazon Transcribe converts audio recordings into written text, enabling automated closed captioning or transcription of customer service calls.
- To convert text back into spoken word, Amazon Polly is a machine learning service that turns text into lifelike speech, allowing developers to build talking applications.
- To break down language barriers, Amazon Translate is a neural machine translation service. Amazon Translate delivers fast language translation for text, enabling dynamic localization of websites and global communications.
Conversational AI and Enterprise Search
- Customer service is increasingly automated through bots. Amazon Lex is an artificial intelligence service for building conversational interfaces. Amazon Lex powers chatbots using voice and text capabilities. Because Amazon Lex uses the same deep learning engine as Amazon Alexa, developers can build highly sophisticated, conversational interactions directly into their own applications.
- Finding information scattered across corporate networks can be incredibly frustrating. Amazon Kendra is an enterprise search service powered by machine learning. Amazon Kendra searches across different internal content repositories to find accurate answers, moving beyond mere keyword matching to actually understand the intent behind a user's question.
The Next Frontier: Generative AI
Traditional ML categorizes and predicts; Generative AI creates. Amazon Bedrock is a fully managed service for building generative AI applications. Instead of building underlying models from scratch, Amazon Bedrock provides access to foundation models through an API. This allows businesses to easily integrate advanced generative capabilities—like drafting emails, summarizing massive documents, or writing code—using models from leading AI startups and Amazon itself, all within the secure perimeter of their AWS environment.

Summary: Mapping Services to Business Needs
To prepare for your CLF-C02 exam, think of these services not as a list of tools, but as an assembly line moving from raw data to predictive intelligence.
| Goal | Relevant AWS Service | Core Function |
|---|---|---|
| Store Data | Amazon S3 | The primary storage layer for the data lake. |
| Move/Prep Data | AWS Glue, AWS Data Pipeline | Glue preps data for ML/analytics (ETL); Pipeline automates movement. |
| Query/Analyze | Athena, Redshift, EMR | Athena (ad-hoc S3 SQL), Redshift (Data Warehouse), EMR (Big Data clusters). |
| Stream/View | Kinesis, OpenSearch, QuickSight | Kinesis (real-time stream), OpenSearch (logs), QuickSight (dashboards). |
| Build Models | Amazon SageMaker | Fully managed environment to build, train, and deploy ML models. |
| Apply Pre-Trained AI | Lex, Rekognition, Polly, etc. | Ready-made intelligence for vision, speech, text, and chat. |
By mastering the distinctions between these services, you validate not just your technical vocabulary, but your ability to translate modern cloud architecture into tangible business value.