Loosely Coupled Microservices
Not sure you’re ready?
Take the ~3-minute readiness diagnostic and see where you stand.
Imagine a bustling restaurant where the waiter who takes your order must also walk to the kitchen, cook the meal, and plate it before returning to the dining room to assist the next customer. This synchronous dependency means a minor delay at the stove immediately halts order-taking across the entire floor. The system is tightly coupled; a failure at any single point triggers a cascading failure for the entire operation. By introducing a simple ticket window, the waiter can instantly hand off the order and return to the customers, while the kitchen staff pulls tickets at their own pace.
This is the fundamental premise of decoupled, event-driven architectures in the cloud. By designing systems where components communicate asynchronously, we isolate failures, enable surgical scaling, and absorb traffic spikes seamlessly. In this guide, we will dissect the mechanics of loose coupling on AWS, exploring how to manage state, expose APIs safely, route messages asynchronously, and orchestrate complex serverless workflows.
To understand distributed cloud architecture, we must first examine how application components remember who you are and how they talk to each other.
The Physics of State
The behavior of an application under heavy load is dictated entirely by how it handles state.
Stateful applications save client data from one request for use in subsequent requests. If a user logs in and adds items to a shopping cart, a stateful web server holds that cart data in its local memory. The inherent flaw here is routing: stateful components often require sticky sessions to maintain client interactions with a specific server instance. If that single instance fails, the user's session is destroyed. Furthermore, sticky sessions create uneven load distribution, defeating the purpose of elasticity.
Conversely, stateless applications do not store client session data between requests. Every incoming HTTP request contains all the context the server needs to process it. Because no local memory is relied upon, stateless components can scale out horizontally by adding identical instances behind a load balancer. When traffic spikes, Auto Scaling simply provisions more identical workers to share the load.
Architectural Imperative: How do we maintain user sessions (like shopping carts) while keeping our compute tier stateless? We move the state to a managed database. Externalizing session state to Amazon DynamoDB enables web servers to remain stateless. For read-heavy or highly transient session data requiring sub-millisecond latency, externalizing session state to Amazon ElastiCache allows an application to behave statelessly while maintaining extreme performance.
Communication and Coupling
When designing microservices, the integration method dictates the system's fragility. Microservices can communicate with each other through well-defined APIs. However, synchronous communication between microservices creates tight coupling. If Service A makes a synchronous API call to Service B, Service A must wait for a response. If Service B crashes, Service A hangs, and the user experiences an error.
To solve this, microservices can communicate with each other through asynchronous messaging queues. By placing a queue between them, asynchronous communication between microservices promotes loose coupling. The producer simply drops a message into the queue and moves on. If the consumer goes offline, the message rests safely in the queue until the consumer recovers. Because of this buffer, decoupled microservices fail independently without causing a system-wide application outage.
Before microservices can communicate internally, they must receive instructions from the outside world. Amazon API Gateway is a fully managed service for creating, publishing, maintaining, monitoring, and securing APIs. It acts as the application's front door.
Crucially, Amazon API Gateway decouples the frontend client interface from backend microservices. A web or mobile client does not need to know the IP addresses or infrastructure details of your backend; it simply calls the Gateway.

Protocols and Integration
Modern applications require diverse communication strategies. Consequently, Amazon API Gateway supports REST, HTTP, and WebSocket API protocols.
- REST/HTTP APIs handle traditional request-response web traffic.
- WebSocket APIs maintain persistent two-way connections, ideal for real-time chat applications or live financial dashboards.
When a request arrives, the gateway must route it to compute. One of the most powerful architectural patterns is serverless computing, where Amazon API Gateway integrates directly with AWS Lambda to create serverless APIs. The gateway translates the incoming HTTP request into a JSON event payload, triggers the Lambda function, and returns the response to the client—all without a single EC2 instance being provisioned.
Routing and Protection
Where your users are located dictates how you configure your endpoints:
- Regional API Gateway endpoints are deployed in the specified AWS Region without a built-in CloudFront distribution. These are ideal for backend-to-backend traffic or when clients reside within the same geographic region.
- Edge-optimized API Gateway endpoints route traffic through Amazon CloudFront edge locations. This allows a user in Tokyo to securely connect to a local edge node, accelerating the TCP/TLS handshake before traffic is routed over the AWS global backbone to your backend in Virginia.
Finally, the gateway acts as a shock absorber. Amazon API Gateway can throttle inbound client requests to prevent backend services from being overwhelmed. By enforcing rate limits, you protect your databases from malicious floods. To further optimize performance, Amazon API Gateway caching reduces the number of calls made to backend endpoint services. If a user requests the daily weather forecast, the gateway can cache the response for a set duration, serving subsequent users instantly and reducing compute costs.
Once a request passes through the API Gateway, it enters the internal nervous system of your architecture. AWS provides two distinct, highly scalable messaging services to facilitate asynchronous communication: Amazon SQS (queuing) and Amazon SNS (publish/subscribe).
Amazon SQS: The Buffer
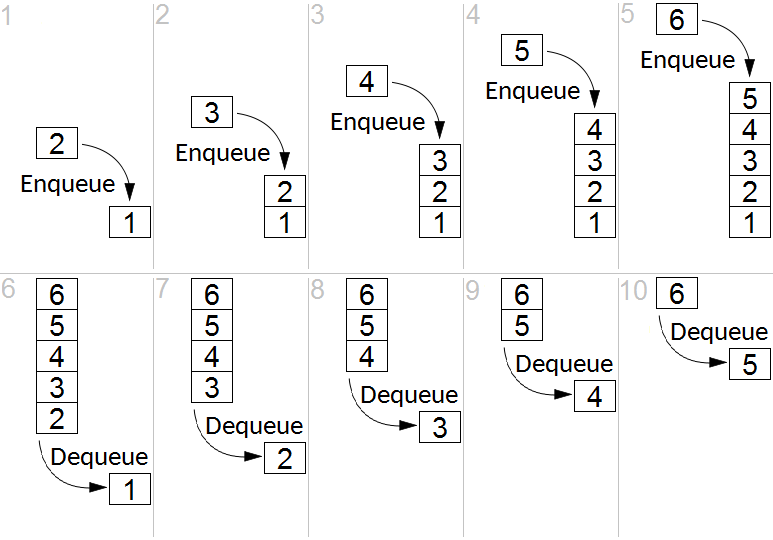
Amazon SQS is a fully managed message queuing service used for decoupling microservices. It operates on a pull-based model: producers drop messages into the queue, and consumers actively poll the queue to retrieve them.
Delivery Guarantees and Ordering
You must choose the correct queue type based on your data constraints:
| Feature | Standard SQS Queues | FIFO SQS Queues |
|---|---|---|
| Delivery Guarantee | Standard SQS queues offer at-least-once message delivery. | FIFO SQS queues guarantee exactly-once message processing. |
| Ordering | Standard SQS queues do not guarantee strict message ordering. | FIFO SQS queues guarantee strict message ordering. |
| Use Case | High-throughput batch processing (e.g., image resizing). | Financial transactions, inventory management. |
Message Lifecycle and Visibility
When a worker pulls a message from the queue, we must ensure another worker doesn't pull the exact same message simultaneously. An SQS visibility timeout hides a message from other consumers while a worker processes that message. If the worker successfully processes the data, it deletes the message from the queue. If the worker crashes, the timeout expires, and the message reappears for another worker to process.
- The default visibility timeout for an Amazon SQS message is 30 seconds.
- The maximum visibility timeout for an Amazon SQS message is 12 hours (useful for massive video rendering tasks).
Sometimes, messages inherently fail due to bad code or corrupted payloads. To prevent an infinite loop of failed processing, dead-letter queues store Amazon SQS messages that cannot be processed successfully after a specified number of attempts. This isolates the "poison pill" messages for developer troubleshooting.
Conversely, you may want to artificially delay processing. Amazon SQS delay queues postpone the delivery of new messages to consumers for a specified duration, which is useful for applications that require a brief grace period (e.g., allowing a user 60 seconds to cancel an order before it is processed).
Whether active or delayed, data cannot live in a queue forever. The Amazon SQS message retention period ranges from 1 minute to 14 days.
Cost Optimization: Long Polling
Polling a queue continuously when it is empty generates unnecessary API calls and inflates AWS bills. To mitigate this, Amazon SQS long polling reduces API costs by waiting for messages to arrive before returning a response. Instead of returning an immediate "empty" response, Amazon SQS long polling can wait up to 20 seconds for a message to arrive in the queue.
Amazon SNS: The Broadcaster
While SQS is a 1-to-1 pull model, Amazon SNS is a fully managed publish and subscribe messaging service. Instead of consumers asking for data, Amazon SNS uses a push-based delivery mechanism to send messages to subscribers.
A single Amazon SNS topic can distribute messages to multiple subscriber endpoints simultaneously. This flexibility is massive. Amazon SNS supports Amazon SQS, AWS Lambda, HTTP/S endpoints, email, and SMS as subscriber types.
Not every subscriber cares about every message. Amazon SNS message filtering allows subscribers to receive only a subset of messages published to a topic based on message attributes. For example, an email subscriber might only receive messages tagged status: critical, ignoring status: info.
The Fan-Out Pattern
By combining SNS and SQS, we achieve one of the most powerful paradigms in cloud architecture. The SNS fan-out pattern involves subscribing multiple Amazon SQS queues to a single Amazon SNS topic.
Imagine a user uploading a video. The web tier publishes a single "VideoUploaded" event to an SNS topic. Subscribed to this topic are three distinct SQS queues. The SNS fan-out pattern allows multiple independent microservices to process the same message asynchronously.
- Queue A feeds an EC2 fleet compressing the video.
- Queue B feeds a Lambda function generating a thumbnail.
- Queue C feeds a microservice updating the user's database record. A single event seamlessly orchestrates three decoupled, parallel operations.
Queues and topics are brilliant for choreography—where microservices react independently to events in the environment. However, some processes require strict orchestration—a centralized conductor managing the exact sequence of steps, tracking progress, and rolling back failures.
AWS Step Functions is a serverless visual workflow orchestration service. It exists entirely to orchestrate multiple AWS services into serverless application workflows.
Unlike an SQS worker pulling a message statelessly, AWS Step Functions maintain the execution state across all steps of a workflow. If an ecommerce checkout process stops halfway through to wait for manual human approval, Step Functions remembers exactly where the workflow paused and what the payload contained.
Writing Workflows and Managing State
To build these orchestrations, AWS Step Functions workflows are defined using the Amazon States Language, a JSON-based structure that defines the flow of your application. Inside this language, you utilize various state types:
- AWS Step Functions Task states represent a single unit of work performed by another integrated AWS service (e.g., invoking a Lambda function, running an ECS task, or inserting a DynamoDB record).
- AWS Step Functions Wait states delay the execution of a workflow for a specified duration or until an exact timestamp.
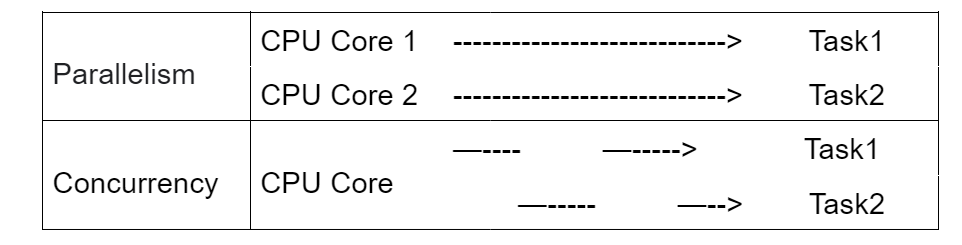
- AWS Step Functions support parallel execution states to run independent branches of a workflow concurrently.
- AWS Step Functions support Map states to process collections of data items dynamically. If you pass an array of 1,000 S3 object keys into a Map state, it spawns 1,000 parallel iterations to process them simultaneously.
Resilience and Error Handling
Distributed systems fail in unpredictable ways: APIs timeout, databases throttle, and network packets drop. AWS Step Functions provide built-in automated retry logic for transient failures. If a Lambda function times out, Step Functions can automatically retry the task with exponential backoff.
If a failure is permanent (e.g., a credit card is declined), AWS Step Functions provide built-in error handling logic. You can configure Catch statements to route the execution down a separate "failure branch," executing compensation logic (like releasing reserved inventory) without writing manual try/catch blocks into your code.
Standard vs. Express Workflows
Finally, you must align the workflow type to the temporal nature of your workload:
| Type | Maximum Duration | Core Design Purpose |
|---|---|---|
| Standard | AWS Step Functions Standard Workflows have a maximum execution duration of one year. | AWS Step Functions Standard Workflows are designed for long-running application processes (e.g., IT approval chains, multi-day media rendering). |
| Express | AWS Step Functions Express Workflows have a maximum execution duration of five minutes. | AWS Step Functions Express Workflows are designed for high-volume event-processing workloads (e.g., IoT data ingestion, real-time stream processing). |
By mastering API Gateway for boundary control, SQS and SNS for asynchronous messaging, and Step Functions for complex orchestration, you possess the tools to construct elegant, highly resilient architectures. You transform fragile, monolithic bottlenecks into fluid, loosely coupled ecosystems that fail gracefully and scale dynamically.
