Benefits of Cloud Services: Availability and Scalability
Not sure you’re ready?
Take the ~3-minute readiness diagnostic and see where you stand.
A traditional on-premises data center operates under rigid physical and financial constraints: a system can only process as much data as its physical hardware allows, and when a localized component fails, the application halts until human intervention occurs. The foundational promise of cloud computing is the dismantling of these physical limitations. By shifting infrastructure to a platform like Microsoft Azure, organizations no longer purchase isolated, finite servers; they lease access to massive, interconnected pools of compute power and storage. This architectural shift radically alters how an organization manages risk and capacity, fundamentally changing the definitions of system availability, scalability, reliability, and predictability. For the project manager launching a global application, the finance director forecasting quarterly infrastructure spend, or the systems engineer designing a resilient database, mastering these four pillars is the absolute bedrock of cloud literacy.
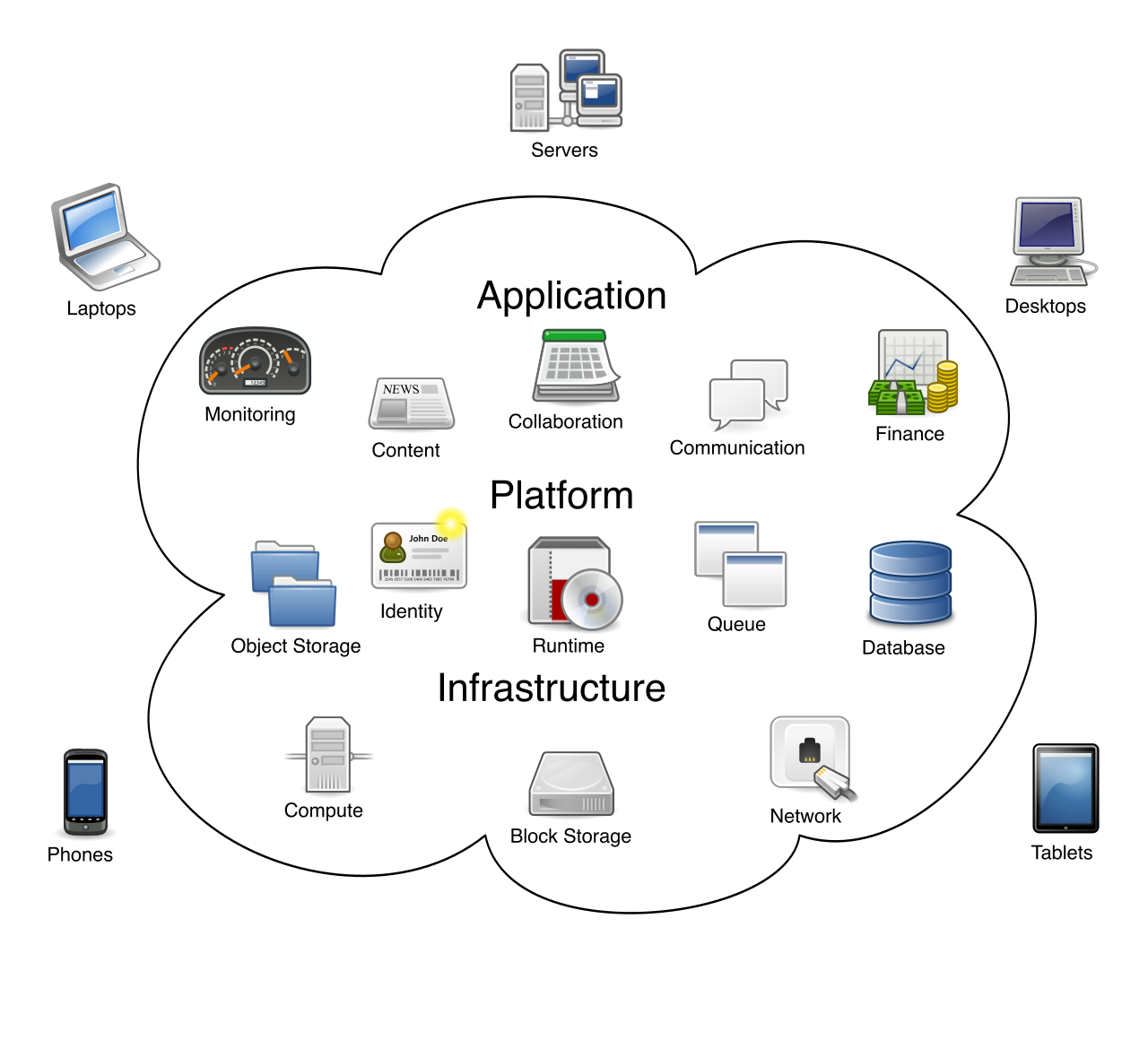
When a business application goes dark, the immediate consequences are lost revenue, fractured customer trust, and derailed productivity. High availability focuses on ensuring maximum continuous uptime for cloud applications and services. Its entire purpose is to minimize system downtime during normal operational periods.
In a traditional server room, high availability requires an organization to purchase duplicate servers, duplicate networking gear, and duplicate power supplies—mostly sitting idle just in case the primary equipment fails. Cloud platforms circumvent this immense capital expense because they utilize highly redundant underlying hardware to achieve high availability. When you deploy a virtual server in Azure, the physical hardware beneath it (the power racks, cooling arrays, and hypervisor nodes) is already replicated. If a hard drive in Microsoft's server rack dies, your workload is instantly shifted to a functioning drive.
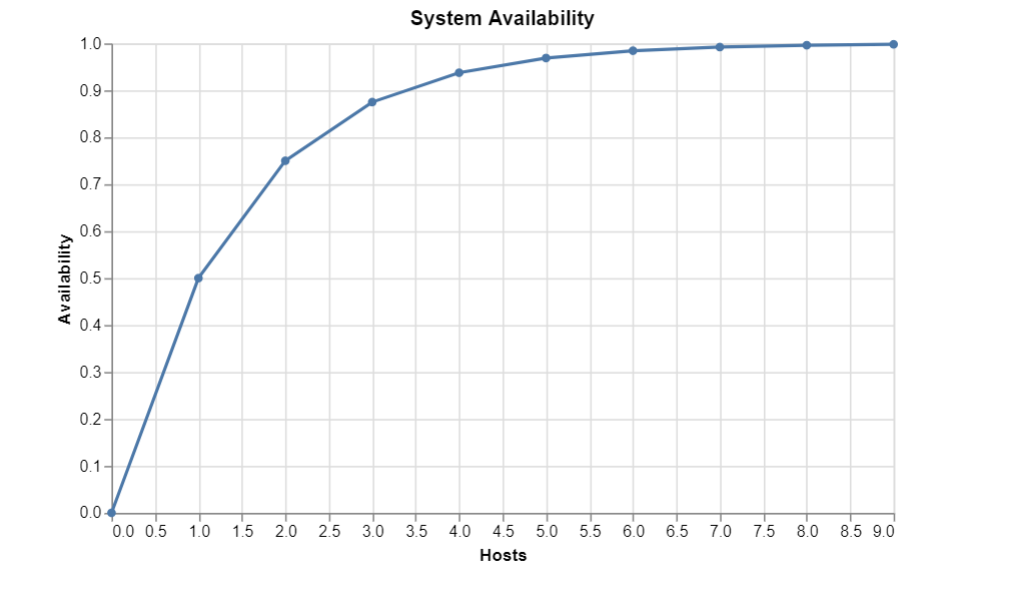
To quantify this promise, providers establish a mathematical contract with the consumer.
A Service Level Agreement (SLA) formally defines the uptime guarantees a cloud provider makes to a customer. If the provider fails to meet this guarantee, they issue a financial credit to the customer.
Azure Service Level Agreement uptime guarantees are typically expressed as percentages such as 99.9% (often called "three nines") or 99.99% ("four nines"). To put this in perspective for a project manager or business stakeholder: an SLA of 99.9% permits roughly 43 minutes of downtime per month, whereas a 99.99% SLA permits barely 4 minutes per month.
Demand for a software service is rarely static. An e-commerce platform sees a massive surge in traffic during the holidays; an accounting portal peaks at the end of the fiscal quarter. Cloud scalability is the ability to adjust computing resources to match varying workload demands. Instead of permanently over-purchasing hardware to handle a temporary peak—a disastrously inefficient use of capital—cloud users can scale their infrastructure precisely to the size of the current workload.
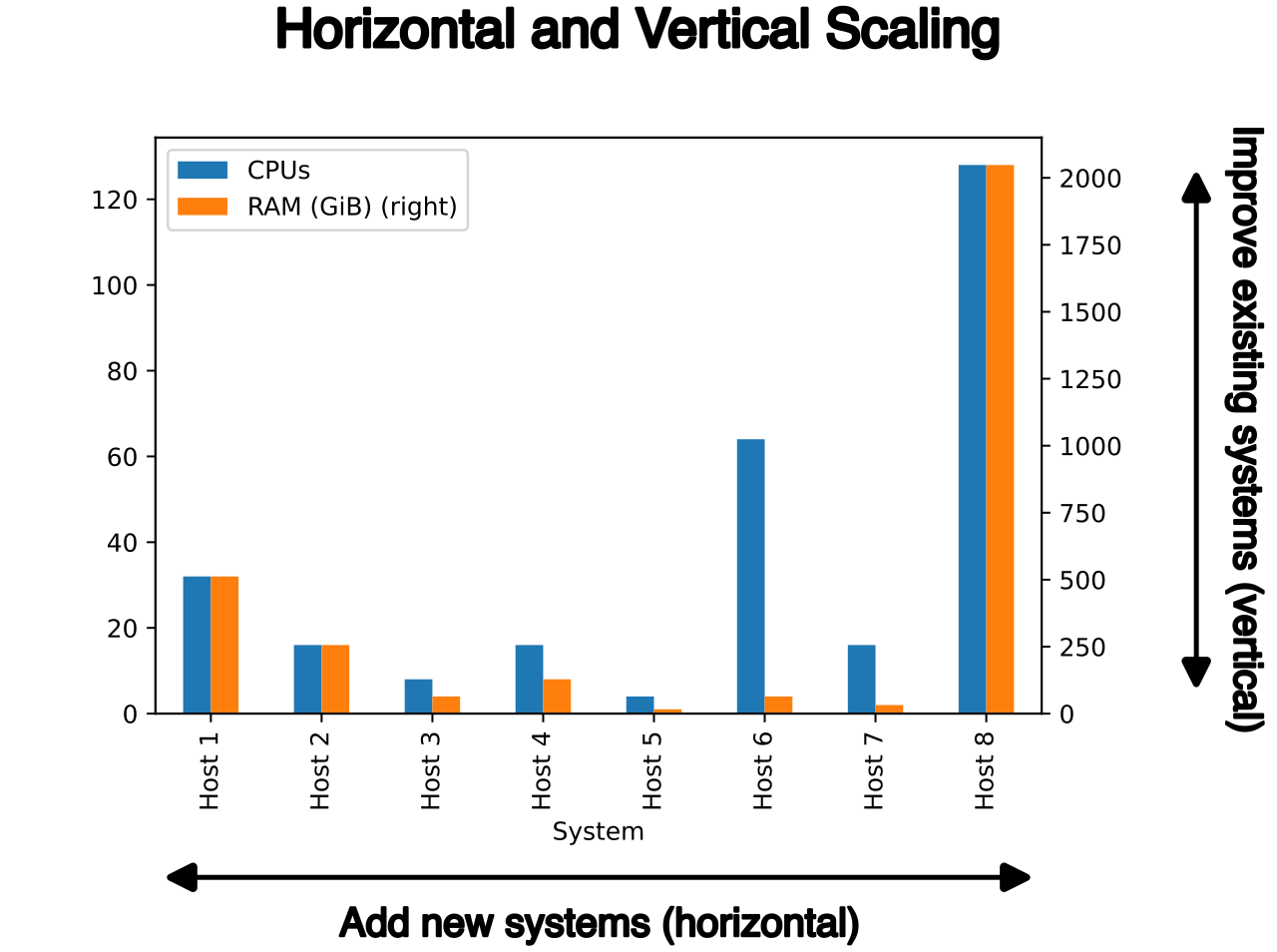
Scalability comes in two distinct architectural models:
Vertical Scaling (Scaling Up / Down)
Vertical scaling involves increasing or decreasing the computing power of a single existing cloud resource. Vertical scaling is commonly referred to as scaling up or scaling down.
Think of vertical scaling as upgrading a vehicle's engine. If a delivery truck is struggling to carry a heavy load up a hill, you swap its V4 engine for a V8. In the cloud, upgrading a virtual machine to a larger size with more RAM or a faster CPU is an example of vertical scaling.
However, vertical scaling has a significant operational constraint: just as you cannot swap a truck's engine while it is driving down the highway, vertical scaling often requires a temporary restart of the specific cloud resource. For a few moments, the machine must shut down, adopt its new hardware profile, and boot back up.
Horizontal Scaling (Scaling Out / In)
Horizontal scaling involves adding or removing distinct instances of a cloud resource. Horizontal scaling is commonly referred to as scaling out or scaling in.
Returning to the truck analogy: instead of upgrading one truck's engine, you simply add a second, identical delivery truck to your fleet. In the cloud, deploying additional identical virtual machines to an application cluster is an example of horizontal scaling.
Because you are adding entirely separate machines to work alongside the original, horizontal scaling typically occurs without causing downtime for the overall application. The original machine continues processing requests while the new machines boot up and join the workload.
| Feature | Vertical Scaling (Up/Down) | Horizontal Scaling (Out/In) |
|---|---|---|
| Mechanism | Adds RAM/CPU to an existing resource | Adds distinct, identical resource instances |
| Downtime | Often requires a temporary restart | Typically occurs without causing downtime |
| Example | Upgrading a VM from 8GB to 32GB RAM | Adding three new VMs to a web cluster |
The Power of Cloud Elasticity
Scalability gives you the ability to change your infrastructure size. Cloud elasticity is the automation of that ability.
Cloud elasticity is the automatic adjustment of scalable cloud resources based on real-time traffic fluctuations. Imagine a supermarket where checkout lanes magically open themselves the moment a line begins to form, and close themselves the moment the store empties out. Elasticity ensures an application maintains consistent performance during sudden traffic spikes without manual intervention. The IT engineering team does not need to wake up at 3:00 AM to manually spin up new servers; the cloud platform senses the CPU strain, scales horizontally automatically, and then scales back in when the traffic subsides, ensuring you only pay for what you actually use.
It is a law of physics that hardware eventually fails. Hard drives degrade, fiber optic cables get severed, and power grids experience localized blackouts. Cloud reliability is the ability of a system to successfully recover from component failures and continue functioning.
If high availability is the percentage of time a bridge is open to traffic, reliability is the bridge's ability to stay open even if a suspension cable snaps. Reliability is broadly categorized into two defensive strategies:
- Fault tolerance is a reliability design that allows an application to operate even if a specific underlying component fails. If an application utilizes three database servers and one suddenly crashes, a fault-tolerant design automatically routes all user traffic to the remaining two servers without the end-user ever noticing an interruption.
- Disaster recovery is a cloud reliability strategy focused on restoring operations after massive geographic or catastrophic failures. While fault tolerance handles the failure of a single hard drive or server rack, disaster recovery dictates how a business survives a hurricane flooding an entire data center.
Microsoft Azure achieves high reliability by allowing customers to distribute workloads across isolated physical data centers. These data centers are grouped into Azure Regions and Availability Zones, complete with independent power, cooling, and networking. By intentionally spreading an application across these physically separated facilities, an organization ensures that even if a natural disaster disables one geographic site, the application continues to run from another.
When migrating to a utility-based computing model—where resources are provisioned on demand—business leaders often harbor two deep anxieties: Will our application perform consistently under pressure? and Will our monthly bill be wildly unpredictable?
Cloud predictability encompasses both consistent system performance and predictable financial costs. Azure provides mechanisms to mathematically forecast and control both variables.
Performance Predictability
Performance predictability ensures that a cloud application delivers consistent user response times regardless of traffic load. If an internal finance dashboard takes two seconds to load on a quiet Tuesday, it should still take two seconds to load on the final day of the fiscal year when every executive in the company is logging in simultaneously.
Cloud platforms achieve performance predictability by utilizing automated load balancing and auto-scaling mechanisms. The load balancer acts as a traffic cop, evenly distributing incoming user requests across all available servers so that no single machine gets overwhelmed. When paired with elastic auto-scaling, the system effortlessly absorbs massive spikes in demand, preserving a flawless, predictable experience for the end-user.
Cost Predictability
Because cloud computing operates on a consumption-based (pay-as-you-go) model, unchecked resources can quickly generate massive bills. For project managers and finance teams, an architecture is only successful if its costs can be accurately modeled.
Cost predictability allows organizations to forecast future cloud spending accurately based on resource consumption. To prevent billing surprises, cloud platforms provide specialized pricing calculators and cost management tools to ensure financial predictability.
Tools like the Azure Pricing Calculator allow architects to build theoretical infrastructure models—calculating the exact monthly cost of a workload down to the cent before a single virtual machine is ever launched. Furthermore, tools like Azure Cost Management allow financial stakeholders to set strict spending budgets, analyze historical burn rates, and receive automated alerts if an engineering team is on track to exceed a designated $5,000 monthly limit.
By leveraging these features, organizations transform IT from a black-box capital expenditure into an agile, highly predictable operational utility.